Heitor Gouvêa
Scaling libs security analysis with differential fuzzing
Table of contents:
Introduction
There have been applications using the Perl language for decades in their back-end’s and platform systems, however the use has been decreasing over time, one consequence of which is the low amount of material on how to make these applications secure, more specifically in modern contexts, another aggravating point related to this is that: we can often see some researchers finding bugs in software used on a large scale that use this language in some of its components, such as:
- RCE in Gitlab’s Bug Bounty program using CVE-2021-22204 which is an issue in Exiftool, a tool written in Perl, found by vakzz;
- RCE on PulseSecure VPN (CVE-2019-11539) by Orange Tsai;
- URL parsing mismatches in Perl libraries, also by Orange Tsai;
- Among many others;
This publication illustrates how the differential fuzzing approach can help in this secure development journey, especially on a large scale, demonstrating the implementation of the technique for identifying logical bugs in several libraries, such as URL parsers and JSON file interpreters.
Although our scope is limited to libraries used by applications built in the Perl language, the technique and approach presented here are replicable to several other interpreted languages such as Python, Ruby, PHP and others.
Background
When we think of safe software development, performing manual analyzes can end up being unfeasible at times, you may need to cover a large attack surface and little depth in one of the stages of your development cycle and to solve this, automated analysis tools can help a lot - or even give you a direction or understanding of the code to conduct a manual analysis, without a doubt the role played by these tools is of great value, saving us time and providing rich information. Unfortunately we have few options related to this topic in Perl.
- Static analysis:
-
Perl::Critic: is the most popular solution when it comes to static analysis, its focus is on code quality but there are still some policies related to code security, but severely limited.
-
AppScan: it is a commercial solution, its free version is extremely limited and with few details. I did some tests, with 4 different projects and I had a total of 40 findings, but all of them were false positives;
-
Semgrep & CodeQL: unfortunately neither of these two wonderful solutions have native Perl support at the moment, maybe in the future we will see some implementation;
-
- Software Composition Analysis:
- ActiveState: another commercial and limited solution of SCA in Perl, although its CVE database is outdated, it still seems to be the best solution currently available;
- Dynamic analysis: at the time this post was written, no product or tool for this purpose was found.
Objective
Given the background, this publication aims to demonstrate how we can use the differential fuzzing technique to conduct security analysis in an automated and large-scale way to find security issues in modern components used by applications developed in Perl.
Differential fuzzing
A technique that can strongly help us on this journey is fuzzing: “is an automated software testing technique that involves providing invalid, unexpected, or random data as inputs to a computer program. The program is then monitored for exceptions such as crashes, failing built-in code assertions, or potential memory leaks.” [1].
More specifically using the differential fuzzing approach due to its ease of implementation and speed, below is illustrated how this approach can be used to identify divergences in some modules, which can lead to the identification of logical bugs that in some contexts can be a security vulnerability.
Differential fuzzing: in this approach we have our seeds being sent to two or more inputs, where they are consumed and should produce the same output. At the end of the test these outputs are compared, in case of divergence the fuzzer will signal a possible failure. [2]
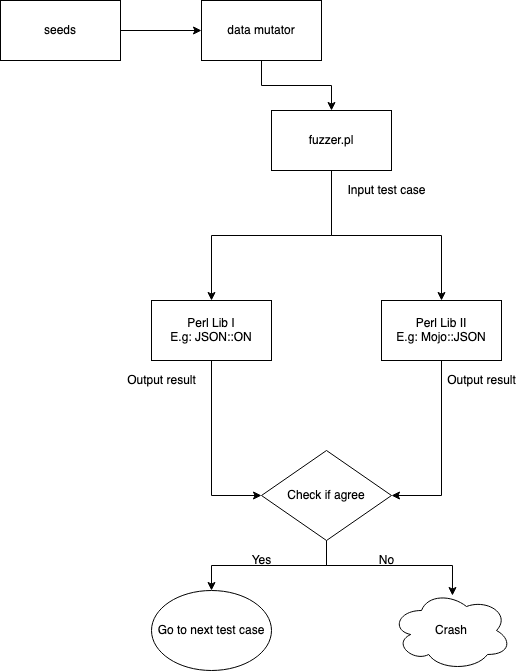
To apply the proposed model, the FuzzPM [3] tool was developed, available in an open-source form under the MIT license.
This project allows us to create cases and fuzzing targets using little effort, using multi-threads during the execution of the tests so that the visualization of the results happens as soon as possible. In the next sections we will see more about using FuzzPM.
Hunting for logic bugs
For practical demonstration and collection of evidence on the functioning of the thesis discussed here, 2 categories of libraries were chosen to serve as our targets, being parsers of URL’s/URI’s and also of JSON objects.
For each of these sections, we will use the following samples from different libraries:
-
JSON Objects: JSON, JSON::ON, JSON::Parse, Mojo::JSON.
-
Parsers of URL’s and URI’s: URI::Simple, Mojo::URL, WWW::Mechanize, HTTP::Tiny, Mojo::UserAgent.
To create your entire fuzzing case, you first need to create your target library as a package, for example:
package Mojo_URI {
use strict;
use warnings;
use Try::Tiny;
use Mojo::URL;
sub new {
my ($self, $payload) = @_;
try {
my $url = Mojo::URL -> new($payload);
return $url -> host;
}
catch {
return undef;
}
}
}
So, you need store your seeds as a file at: ./seeds/your-seeds.txt. And the last part is your case as a YAML file, follow this structure:
test:
seeds:
- path/to/seeds-file.txt
libs:
- First_Target
- Second_Target
- Third_Target
For example, for our first case, the following YAML file was constructed and is supplied to the fuzzer via the parameter “–case”:
test:
seeds:
- seeds/urls-radamsa.txt
libs:
- Mojo_URI
- Tiny_HTTP
- Mojo_UA
- Mechanize
- Lib_Furl
- Simple_URI
The output of the fuzzing process is similar to the following example:
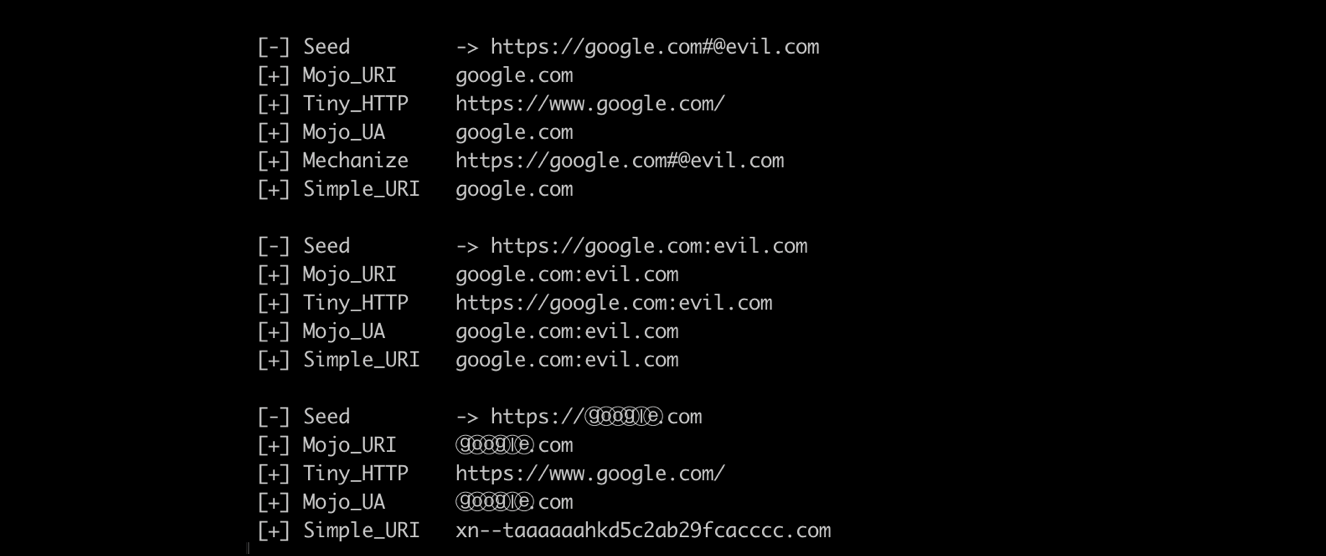
Here we can already see some of the advantages of this approach, such as ease of implementation and processing speed.
Abusing URL parsers
In modern times, practically every application or software deals with URLs at some point, this is because we have had a great advance in relation to the capacity of the internet, from its reach to its performance, so dealing with third parties applications is no longer a bottleneck and has become a feature of modern applications because that way it is possible to share responsibility with more resources, making access to components faster and more distributed.
To support this reality, developers invested energy in the development of some URI parsing and HTTP engines libraries for the language, currently there are more than a dozen in this category alone when us talk about Perl Libs.
As already demonstrated in previous research, such as that of Orange Tsai [5] (cited at the beginning of this text) and also by the Claroty team [8], it is common for these components to have divergences between, which can be explored during the cases of vulnerabilities such as SSRF, CFRL injection and open redirect.
Through the seeds evidenced during the research produced by Orange Tsai, replicating them but looking at the divergences with the libraries mentioned above, it was possible to find two security issues that are possible to exemplify in real scenarios.
URL-Encoded Confusion:
[-] Seed -> https://ⓖⓞⓞⓖⓛⓔ.com
[+] Mojo_URI -> ⓖⓞⓞⓖⓛⓔ.com
[+] Tiny_HTTP -> https://www.google.com/
[+] Mojo_UA -> ⓖⓞⓞⓖⓛⓔ.com
[+] Simple_URI -> xn--taaaaaahkd5c2ab29fcacccc.com
Scheme Confusion:
[-] Seed -> https://[email protected]:[email protected]
[+] Mojo_URI -> evil.com:[email protected]
[+] Tiny_HTTP -> https://[email protected]:[email protected]
[+] Mojo_UA -> evil.com:[email protected]
[+] Simple_URI -> google.com
A practical example of how an application could become vulnerable to one of these attacks would be the use of these different libraries, one for Passing the URL and verification, other for the request itself, such as:
#!/usr/bin/env perl
use 5.018;
use strict;
use warnings;
use URI;
use Try::Tiny;
use HTTP::Tiny;
use Mojolicious::Lite -signatures;
get "/" => sub ($request) {
my $endpoint = $request -> param("endpoint");
if ($endpoint) {
my $uri = URI -> new($endpoint);
if ($uri -> host() ne "google.com") {
try {
my $getContent = HTTP::Tiny -> new() -> get($endpoint);
if ($getContent -> {success}) {
return ($request -> render (
text => "ok"
));
}
}
catch {
return ($request -> render (
text => "error"
));
}
}
}
};
app -> start(); # perl app.pl daemon -m production -l http://\*:8080
What would happen here is that, an attacker requesting the application with the following payload:
https://target.com/?endpoint=https://ⓖⓞⓞⓖⓛⓔ.com
It would be able to bypass the check based on the blocklist, later the app would make the request for the google.com domain. We could take advantage of these divergences in SSRF scenarios.
JSON interoperability
To enable the process of communication between different applications, it was necessary to create some standards for transporting objects, among the most famous are XML and JSON. The first was widely used after its release in 1996, after that JSON was released in 2002 and gained a lot of popularity, I dare say that it is the standard adopted on a large scale today.
As a consequence of this fact, the creation of libraries to parse these objects was necessary and several people realized this, generating a large number of different libraries.
Quite frankly, it will be difficult for you to interact directly with an API written in Perl, the chances are greater that these APIs are internal, consumed by another back-end and this is good, as it opens up room for exploring JSON interoperability contexts [4], making room for techniques of “Attacking Secondary Contexts in Web Applications” [9].
As there are many modules in Perl to handle this type of information, the margin of attack ends up being quite large. Here we will cover the 4 most used modules based on CPAN; In this case, 8 different JSON inputs were provided, taken from Bishop Fox’s research on the subject [5]. To better illustrate, I will leave a table below with all the detailed view of the outputs:
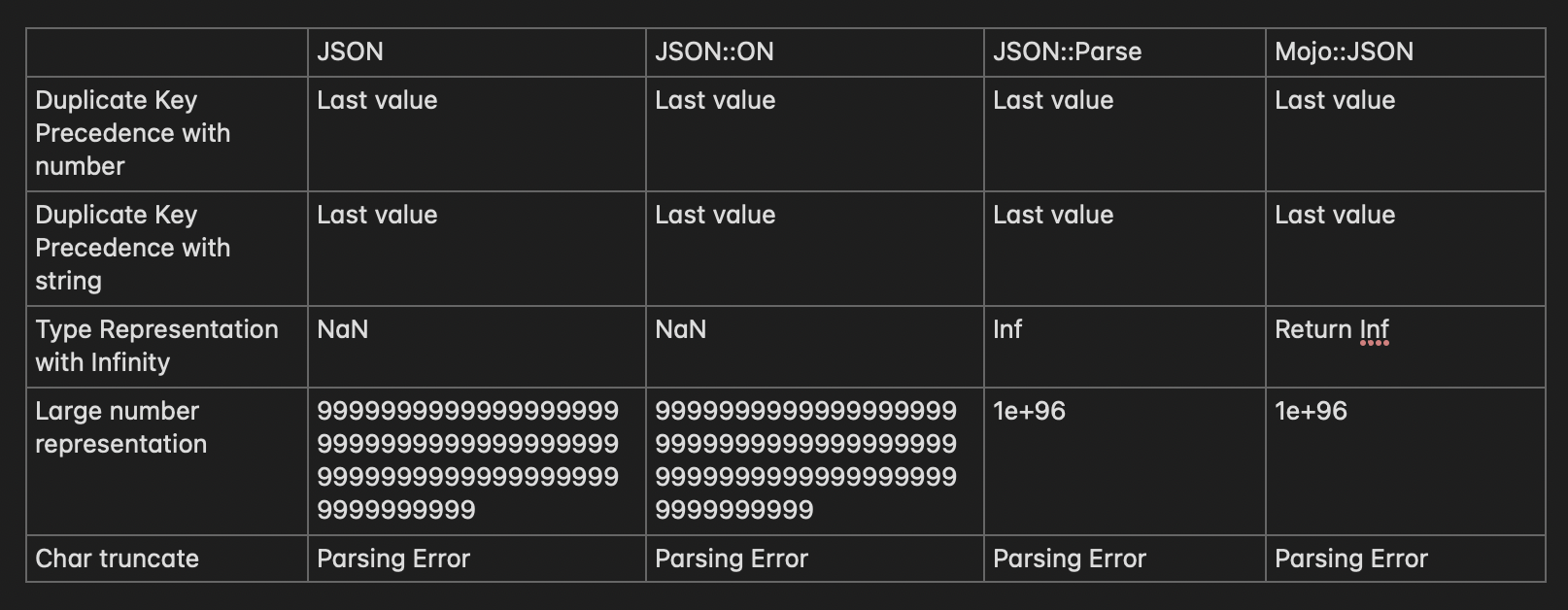
We can notice that there are two divergences, being in: Type Representation with Infinity and Large number representation;
These divergences can be used to exploit NaN Injection [[10]], a technique that has low popularity at the moment but can be used to exploit logic vulnerabilities or even denial of service in some languages such as Python, Ruby, Perl, PHP and others.
For educational purposes, let’s illustrate a possible exploit case:
#!/usr/bin/env perl
use 5.018;
use strict;
use warnings;
my %account = (
name => "",
money => 1000
);
sub buy_items {
my @items = (
{name => "web hacking book", price => 100, id => 1},
{name => "severino license", price => 50, id => 2},
{name => "home made hacking tool", price => 200, id => 3},
{name => "shell", price => 100000, id => 4}
);
foreach my $item (@items) {
print "ID: @$item{id}\n";
print "Product: @$item{name}\n";
print "Price: @$item{price}\n\n";
}
print "\nItem ID? ";
chomp (my $itemid = <STDIN>);
if ($itemid > 0 && $itemid < 5) {
print "\nHow many? ";
chomp (my $many = <STDIN>);
my $total = $items[$itemid - 1 ] -> {price} * $many;
print "[+] TOTAL ===> $total\n";
if ($many <= 0) {
print ":/\n";
}
else {
if ($total > $account{money}) {
print "You do not have enough money :(\n";
}
else {
$account{money} -= $total;
print "You buy item", $items[$itemid - 1 ] -> {name}, "\n";
if ($items[$itemid] -> {name} eq "shell") {
system ("/bin/sh");
}
}
}
}
else {
print "Invalid!\n";
exit();
}
}
sub show_account_info {
print "\n[+] Name: $account{name} \n[+] Money: $account{money}\n";
}
sub main {
print "\nWhat is your name? ";
chomp ($account{"name"} = <STDIN>);
while (1) {
print "\n0. buy items \n1. show account info\n2. exit\n? ";
chomp (my $choice = <STDIN>);
if ($choice == 0) {
buy_items();
}
elsif ($choice == 1) {
show_account_info();
}
elsif ($choice == 2) {
exit();
}
}
}
main();
This small piece of code is a simple implementation of a mechanism for purchasing some items, given that the user enters his name at the beginning of the journey and has an initial balance of “10000”.
Reading the code, we can see that our user can use their initial balance to buy almost all products except item 4 because it costs “10,000”. If he could do this, he could get a shell on the machine that hosts the application, because after this one made a system function is called (this behavior is only for educational purposes).
We have 3 entry-points here:
- When we inform our name;
- When we say which item we want to buy;
- How much we want to buy;
The name as a possible entrypoint can be discarded, as this information is not used for the logic of the algorithm. The implementation regarding which item we want to buy would also not lead us to be able to acquire item 4.
The entrypoint related to the quantity of the item allows us to do this in two ways. The first possibility being:
- Inform a fractional amount enough so that after multiplied by the value of the product, it was less than the balance;
- Inform NaN or a representation thereof;
As we can see in the table, we could use two cases of divergence to generate an input like “NaN” for this application if it were an internal service, either through the parsing of json objects using the JSON or JSON::ON libs to process an attribute that had as its value a “Type Representation with Infinity”.
Conclusion
Through the implementation of the differential fuzzing technique in the FuzzPM project, we can detect some divergences in URL Passing libraries and JSON objects, divergences that have a good possibility of exploitation in real applications as demonstrated in each of the sections and if this is done, the impact can be critical.
References
- [1] https://en.wikipedia.org/wiki/Fuzzing
- [2] https://en.wikipedia.org/wiki/Differential_testing
- [3] https://github.com/htrgouvea/fuzzpm
- [4] https://labs.bishopfox.com/tech-blog/an-exploration-of-json-interoperability-vulnerabilities
- [5] https://www.blackhat.com/docs/us-17/thursday/us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages.pdf
- [6] https://defparam.medium.com/finding-issues-in-regular-expression-logic-using-differential-fuzzing-30d78d4cb1d5
- [7] https://github.com/orangetw/Tiny-URL-Fuzzer
- [8] Exploiting URL Parsers: the good, bad, and inconsistent by CLAROTY
- [9] Attacking Secondary Contexts in Web Applications by Sam Curry
- [10] https://www.tenable.com/blog/python-nan-injection